
I've spent the past year watching agents forget. Not dramatically no error messages, no crashes just a quiet drift. A customer mentions a knee injury on Monday, and by Thursday the fitness bot is recommending squats. A legal assistant confidently cites a case that was overturned two years ago. The model didn't "forget" in any human sense; it simply never had the architecture to remember.
This is what I've come to call the memory problem. While LLMs have scaled to trillions of parameters, their ability to maintain coherent memory across sessions remains a fundamental bottleneck. The context window that fixed-size buffer of tokens the model can "see" is not only finite but computationally expensive: attention mechanisms scale $O(n^2)$ with sequence length, meaning larger contexts come with quadratically growing costs.1
Retrieval-Augmented Generation (RAG) was supposed to solve this, or so the theory went. The promise was simple: instead of stuffing everything into the prompt, retrieve what you need dynamically. But as we've deployed RAG systems at scale, we've discovered that flat vector-based retrieval struggles with temporal reasoning ("what happened before X?") and multi-hop synthesis ("how does X relate to what we discussed last month?").
This post is my attempt to make sense of that failure and the increasingly sophisticated attempts to fix it. I'll trace the evolution from naive RAG to what researchers are now calling Agent Memory, focusing not just on what each paradigm is, but on why each fails and what that failure teaches us.
RAG is Dead, Long live RAG!
Retrieval-Augmented Generation, introduced by Lewis et al. in 2020, fundamentally changed how we think about grounding LLM outputs in external knowledge.2 The architecture is deceptively simple: embed a query, retrieve similar documents from a vector database, and concatenate those documents with the prompt before generation.
The Basic Pipeline
If you strip away the complexity, traditional RAG follows a four-stage process:
- Indexing: Documents are chunked into fixed-size segments (typically 512-1024 tokens), each embedded into a dense vector representation.
- Storage: Vectors are indexed in a vector database (Pinecone, Weaviate, Qdrant) optimized for approximate nearest neighbor (ANN) search.
- Retrieval: At query time, the user's question is embedded and matched against stored vectors using cosine similarity.
- Generation: Retrieved chunks are injected into the prompt as context for the LLM.
For simple factual queries, this works remarkably well. "What is the capital of France?" becomes a lookup problem, and semantic similarity does the heavy lifting.3
Here's what a minimal implementation looks like stripped down to just the essentials:
class BasicRAGPipeline:
"""Minimal RAG implementation showing the 4-stage process."""
def __init__(self, embedding_model, vector_db, llm):
self.embedder = embedding_model
self.db = vector_db
self.llm = llm
def index(self, documents: list[str], chunk_size: int = 512):
"""Stage 1 & 2: Chunk, embed, and store."""
for doc in documents:
chunks = [doc[i:i+chunk_size] for i in range(0, len(doc), chunk_size)]
for chunk in chunks:
vector = self.embedder.encode(chunk)
self.db.upsert(id=hash(chunk), vector=vector, metadata={"text": chunk})
def query(self, question: str, top_k: int = 3) -> str:
"""Stage 3 & 4: Retrieve and generate."""
query_vector = self.embedder.encode(question)
results = self.db.search(query_vector, limit=top_k) # ANN search
context = "\n---\n".join([r.metadata["text"] for r in results])
prompt = f"Context:\n{context}\n\nQuestion: {question}\nAnswer:"
return self.llm.generate(prompt)Where Flat RAG Breaks Down
However, production deployments have revealed limitations that simple benchmarks fail to expose. In my experience, three failure modes dominate:
The most insidious is what I call the "Frankenstein Context" when the retriever stitches together semantically relevant but structurally incoherent snippets. In code generation, you get a function definition without its imports or parent class. The LLM, trained to produce fluent output, fills the gaps by hallucinating. The context is relevant; the structure is broken.4
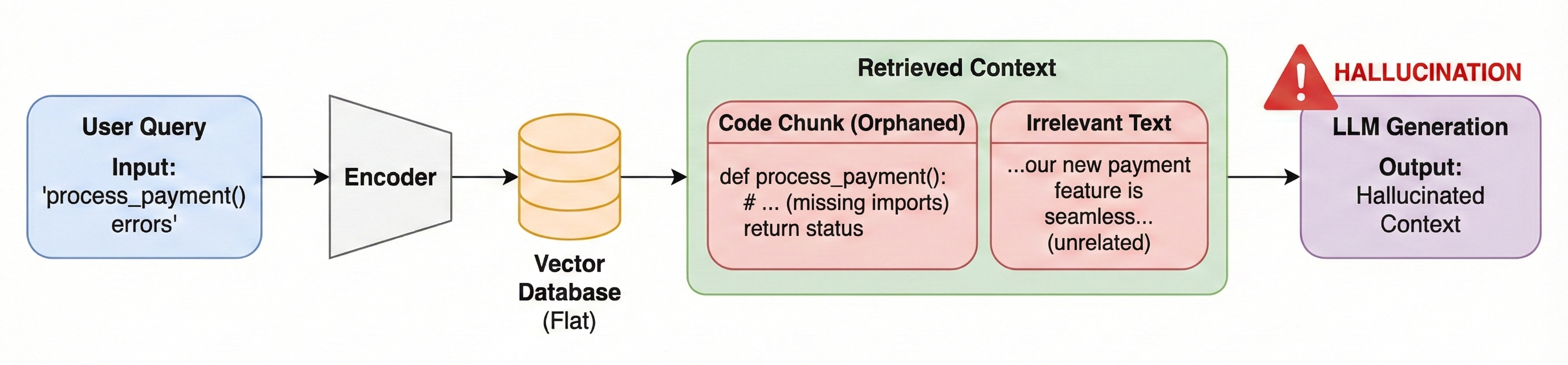
There's also a temporal problem. Vector similarity doesn't encode time. Consider a user who says "I love Adidas shoes" in January, then "My Adidas broke, I now prefer Puma" in July. When later asked "What shoes should I buy?", flat RAG retrieves both statements based on semantic similarity to "shoes" often prioritizing the older, more established fact. The system lacks any concept of fact invalidation: the understanding that new information can override old.
One approach to solving this is to give facts explicit validity windows:
from datetime import datetime
from dataclasses import dataclass
@dataclass
class TemporalFact:
"""A fact with explicit validity window for temporal reasoning."""
content: str
valid_from: datetime
valid_to: datetime | None # None = still valid
supersedes: str | None # ID of fact this invalidates
def resolve_temporal_conflict(facts: list[TemporalFact], query_time: datetime) -> TemporalFact:
"""
Given multiple facts about the same entity, return the one valid at query_time.
Solves the 'Adidas vs Puma' problem by respecting temporal ordering.
"""
valid_facts = [
f for f in facts
if f.valid_from <= query_time and (f.valid_to is None or f.valid_to > query_time)
]
# Return most recent valid fact
return max(valid_facts, key=lambda f: f.valid_from)And then there's the attention problem. Despite the marketing of "infinite" context windows, LLMs exhibit a distinct attention budget. Liu et al. (2023) showed that retrieval performance follows a U-shaped curve: information at the very beginning (primacy) and end (recency) of prompts is recalled accurately, but the middle becomes a "dead zone."6 Information buried there is frequently ignored even when correct answers are present in context.
Finally, flat retrieval can't do relational reasoning. The question "Find products by the same brand as the item in my cart" requires connecting entities across documents. Vector search retrieves chunks that mention brands, but it cannot traverse relationships between them. For that, you need structure.
GraphRAG: Adding Structure to RAG
So flat retrieval struggles with relationships and time. The natural response and one that Microsoft Research formalized in their 2024 work is to give the retrieval system structure. If vectors can't traverse relationships, maybe a graph can.7
From Chunks to Entities
The core insight of GraphRAG is to stop treating documents as bags of tokens. Instead, we extract:
- Entities: Named concepts (people, organizations, products, events)
- Relationships: Directed edges with semantic labels (WORKS_FOR, PURCHASED, LOCATED_IN)
- Claims: Factual assertions grounded in source text
This extraction is typically performed by an LLM prompted to identify entities and relationships, though specialized NER models can work too.8 Here's a simplified extraction function:
EXTRACTION_PROMPT = """
Extract entities and relationships from the following text.
Return JSON: {"entities": [...], "relations": [...]}
Text: {text}
"""
def extract_graph_triplets(text: str, llm) -> dict:
"""
LLM-based entity and relationship extraction for GraphRAG indexing.
Each relation is a (source, predicate, target) triplet.
"""
response = llm.generate(EXTRACTION_PROMPT.format(text=text))
parsed = json.loads(response)
# Validate and deduplicate
entities = {e["name"]: e for e in parsed["entities"]}
relations = [
(r["source"], r["predicate"], r["target"])
for r in parsed["relations"]
if r["source"] in entities and r["target"] in entities
]
return {"entities": list(entities.values()), "relations": relations}Community Detection and Hierarchical Summarization
A key innovation in Microsoft's GraphRAG is the application of community detection algorithms (typically Leiden) to cluster related entities. Each community is then summarized, creating a hierarchical "Theme Tree" that enables answering both local queries ("What did John say about the project?") and global queries ("What are the main themes across all quarterly reports?").9
| Aspect | VectorRAG | GraphRAG |
|---|---|---|
| Data Unit | Text Chunk | Entity-Relationship Triplet |
| Retrieval Logic | Semantic Similarity (k-NN) | Graph Traversal + Community Summarization |
| Multi-hop Reasoning | Poor | Native |
| Global Understanding | None | Via Community Summaries |
| Indexing Cost | Low (embedding only) | High (LLM extraction calls) |
| Explainability | Black box similarity scores | Visible traversal paths |
The Trade-offs
GraphRAG is not a free lunch. I've found three pain points in practice:
First, there's the construction overhead. Entity extraction requires LLM calls that scale linearly with corpus size. For large document collections, indexing costs can dominate operational budgets.10
Second, most GraphRAG systems assume a relatively stable knowledge base. When entities change frequently user preferences, stock prices, project statuses the graph requires expensive re-indexing or complex update propagation. This is the static graph problem.
Third and this one is subtle the quality of extracted entities depends heavily on extraction prompts. Poorly tuned prompts lead to hallucinated edges: relationships that don't exist in the source text, which then pollute retrieval down the line.
Agentic RAG: From Retrieval to Reasoning
Here's the thing both VectorRAG and GraphRAG get wrong: they treat retrieval as a single-shot pipeline stage. The system retrieves once based on the user's query, then generates. But what if the query is ambiguous? What if the first retrieval reveals that more information is needed?
This is where Agentic RAG enters the picture. Instead of retrieval being a fixed step, it becomes a tool available to an autonomous agent one that can reformulate queries, route to different knowledge sources, and iterate until it has sufficient context.11
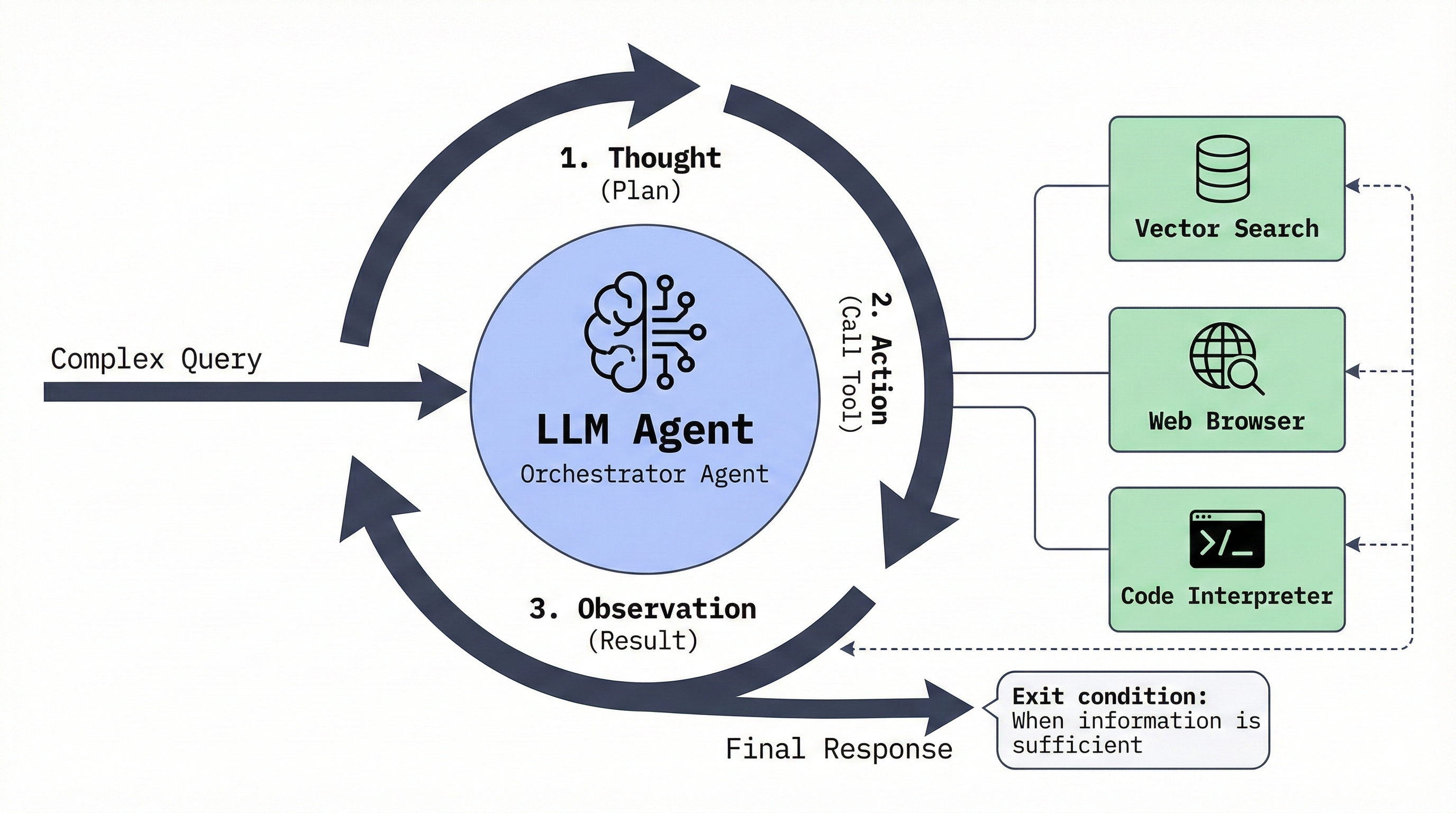
The ReAct Pattern
Most Agentic RAG implementations follow the ReAct (Reasoning + Acting) paradigm, introduced by Yao et al. (2023).12 The agent produces a cycle of Thought → Action → Observation. The "Action" might be a search query, a tool call, or a memory lookup. The "Observation" is the result, which informs the next "Thought." Here's what that looks like:
Thought: The user is asking about their order status. I need to check the order database.
Action: search_orders(user_id="12345", status="pending")
Observation: Found 2 pending orders: Order #789 (shipping), Order #790 (processing)
Thought: I have the order information. I can now answer the user.
Action: respond("You have 2 pending orders...")Multi-Agent Architectures
Complex tasks often benefit from specialized agents: a "Researcher" that queries external APIs, a "Coder" that writes scripts, a "Reviewer" that validates outputs. Frameworks like LangGraph and LlamaIndex orchestrate these agents in graph-based workflows.
The key insight here is that typed state contracts can prevent many failure modes. Here's a simplified example:
from typing import TypedDict
from langgraph.graph import StateGraph, END
class AgentState(TypedDict):
"""Typed state prevents Schema Hallucination failures."""
query: str
retrieved_docs: list[str]
draft_response: str
review_score: float
final_response: str
def build_agent_graph() -> StateGraph:
"""
LangGraph orchestration with explicit type contracts.
Each edge validates state schema before transition.
"""
graph = StateGraph(AgentState)
graph.add_node("researcher", researcher_agent)
graph.add_node("writer", writer_agent)
graph.add_node("reviewer", reviewer_agent)
graph.add_edge("researcher", "writer")
graph.add_conditional_edges(
"reviewer",
lambda s: "writer" if s["review_score"] < 0.8 else "END",
{"writer": "writer", "END": END}
)
return graph.compile()Why Multi-Agent Systems Fail: The MAST Taxonomy
This is where things get interesting and humbling. A comprehensive study of over 1,600 multi-agent system execution traces identified a taxonomy of failures known as MAST.14 The failure profile reveals something uncomfortable: building multi-agent systems means reintroducing distributed systems complexity into AI.
The researchers identified three failure categories:
Specification Failures (Interface Mismatch)
These are failures where valid individual agent outputs become invalid system inputs. Two examples:
- Schema Hallucination: Agent A outputs JSON with key
user_id, but Agent B expectsuserId. Despite semantic correctness, the strict type check fails. - Context Leakage: An upstream agent passes raw prompt instructions (system prompt residue) into the output, which the downstream agent interprets as new user commands. This is effectively a privilege escalation vulnerability within the graph.
Coordination Failures (State & Concurrency)
These failures arise from the distributed nature of the agent graph:
- Cyclic Deadlock: In cyclic graphs (e.g., Critic $\leftrightarrow$ Generator loops), if the stopping condition (e.g.,
score > 0.9) is unreachable due to model capacity limits, the system spins until the token budget is exhausted. - Stale Read/Write: Agent A reads
Memory[Key_X]. Agent B updatesMemory[Key_X]. Agent A acts on the stale value. Unlike standard databases, LLM context windows do not support ACID transactions natively.
One mitigation is to borrow from database design here's a simple optimistic locking pattern:
class MemoryStore:
"""Memory store with optimistic concurrency control."""
def __init__(self):
self._data: dict[str, tuple[any, int]] = {} # key -> (value, version)
def read(self, key: str) -> tuple[any, int]:
"""Returns (value, version) for later CAS."""
return self._data.get(key, (None, 0))
def write(self, key: str, value: any, expected_version: int) -> bool:
"""
Compare-And-Swap: Only writes if version matches.
Prevents stale read/write skew in concurrent agent graphs.
"""
current_value, current_version = self._data.get(key, (None, 0))
if current_version != expected_version:
return False # Conflict detected caller must retry
self._data[key] = (value, current_version + 1)
return TrueVerification Failures (The Silent Propagator)
These are the sneakiest. LLMs rarely output low confidence scores for hallucinations. A "Fact Checker" agent often validates a hallucination because the hallucination is semantically consistent, even if factually grounded in nothing. Similarly, most chains lack deterministic assertions if the "Python Writer" agent generates code that is syntactically correct but functionally void (e.g., pass in a critical loop), the "Reviewer" agent, focusing on linting errors, often approves it.
Aside: In production LangGraph deployments, we've repeatedly seen agents enter "reasoning loops" repeatedly attempting the same failed action. Without explicit circuit breakers, the graph hits its recursion limit and crashes.15 This is not a theoretical concern; it's a Tuesday.
Agent Memory: Towards Stateful Cognition
Agentic RAG enables better information access within a task, but it doesn't solve continuity between tasks. When the conversation ends, the agent forgets. A true cognitive architecture requires persistent state preferences, learnings, and history that survive across sessions.
This is where the literature starts using the term Agent Memory though, as Letta's team has pointed out, the term does a lot of conceptual work.16 What we're really talking about is the difference between retrieval (a read-only operation) and memory (a read-write system with state management and conflict resolution).
The Cognitive Science Framework
Recent research has moved beyond simple "short-term vs. long-term" distinctions to a functional taxonomy derived from cognitive science. Packer et al. (2024) propose five memory types:17
- Sensory/Buffer Memory: Raw input before processing the message queue.
- Working Memory: The active context window. Finite, expensive, aggressively managed.
- Episodic Memory: Specific sequences of past events ("User asked about Python yesterday").
- Semantic Memory: Generalized facts consolidated from episodes ("User prefers Python over Java").
- Procedural Memory: Implicit knowledge of how to perform tasks encoded in prompts and learned tool patterns.
The insight here is that episodic memories should consolidate into semantic facts over time. Here's a simplified implementation of that consolidation:
from collections import defaultdict
def consolidate_episodes_to_facts(
episodes: list[dict],
llm,
consolidation_threshold: int = 3
) -> list[str]:
"""
Cognitive consolidation: Convert repeated episodic patterns into semantic facts.
Mimics biological memory consolidation during sleep.
"""
# Group episodes by extracted entities
entity_mentions = defaultdict(list)
for ep in episodes:
for entity in extract_ner(ep["content"]):
entity_mentions[entity].append(ep)
facts = []
for entity, mentions in entity_mentions.items():
if len(mentions) >= consolidation_threshold:
# LLM synthesizes a durable fact from multiple episodes
prompt = f"Summarize what we know about '{entity}' from these interactions:\n"
prompt += "\n".join([m["content"] for m in mentions])
fact = llm.generate(prompt + "\n\nSynthesized fact:")
facts.append(fact)
return factsSelf-Managing Memory Architectures
One of the more interesting ideas I've encountered is the "LLM as Operating System" paradigm. The analogy: treat the LLM as a CPU, the context window as limited RAM, and external storage as Disk.
In this architecture, the agent becomes self-aware of its context limits. It uses self-editing tools to actively manage what stays in working memory and what gets offloaded to persistent storage. This contrasts sharply with standard RAG, where an external retriever blindly pushes content into the context. In self-managing architectures, the agent manages its own cognitive state.
The key capabilities that differentiate modern memory systems include:
- Adaptive Updates: When new information contradicts old, the system identifies conflicts and updates records rather than blindly appending
- Temporal Awareness: Facts aren't just true they're true at a specific time, enabling distinction between ephemeral details and durable facts
- Intelligent Decay: Less relevant information naturally "fades," while important facts are reinforced
- Self-Editing: The agent can modify its own memory during reasoning, not just during explicit write operations
Here's what a simple working memory manager might look like:
class WorkingMemoryManager:
"""
Manages the finite context window by evicting low-salience items.
Implements the 'LLM as Operating System' paradigm.
"""
def __init__(self, max_tokens: int, embedding_model):
self.max_tokens = max_tokens
self.embedder = embedding_model
self.buffer: list[dict] = [] # {"content": str, "salience": float, "tokens": int}
def add(self, content: str, salience: float):
tokens = count_tokens(content)
self.buffer.append({"content": content, "salience": salience, "tokens": tokens})
self._evict_if_needed()
def _evict_if_needed(self):
"""Evict lowest-salience items until within budget."""
while sum(item["tokens"] for item in self.buffer) > self.max_tokens:
# Evict item with lowest salience (offload to long-term storage)
self.buffer.sort(key=lambda x: x["salience"])
evicted = self.buffer.pop(0)
persist_to_long_term_memory(evicted["content"])
def get_context(self) -> str:
"""Returns current working memory as context string."""
return "\n".join([item["content"] for item in self.buffer])A Word of Caution: The Symbol Grounding Problem
Despite all these advances, cognitive science offers a sobering critique. LLMs still face what philosophers call the Symbol Grounding Problem. As Luciano Floridi has analyzed, LLMs process symbols based on statistical correlations without sensorimotor connection to reality.23
LLMs do not "refer" to entities; they "re-quote" patterns from training data. RAG, in this framing, is just a dynamic re-quotation engine. And critically, biological memory is grounded in episodic context sensory, emotional, and temporal details that give facts meaning. Current AI memory systems strip away that grounding, which may be why they still struggle with causality, contradiction, and significance.
+1 for Context Engineering
This is perhaps the most underrated insight of the past year. As we moved into 2025, the industry briefly believed that massive context windows (1M+ tokens) would make RAG obsolete. This hypothesis has been falsified by production failures. Context is not storage it is a finite "attention budget" that must be engineered with precision.24
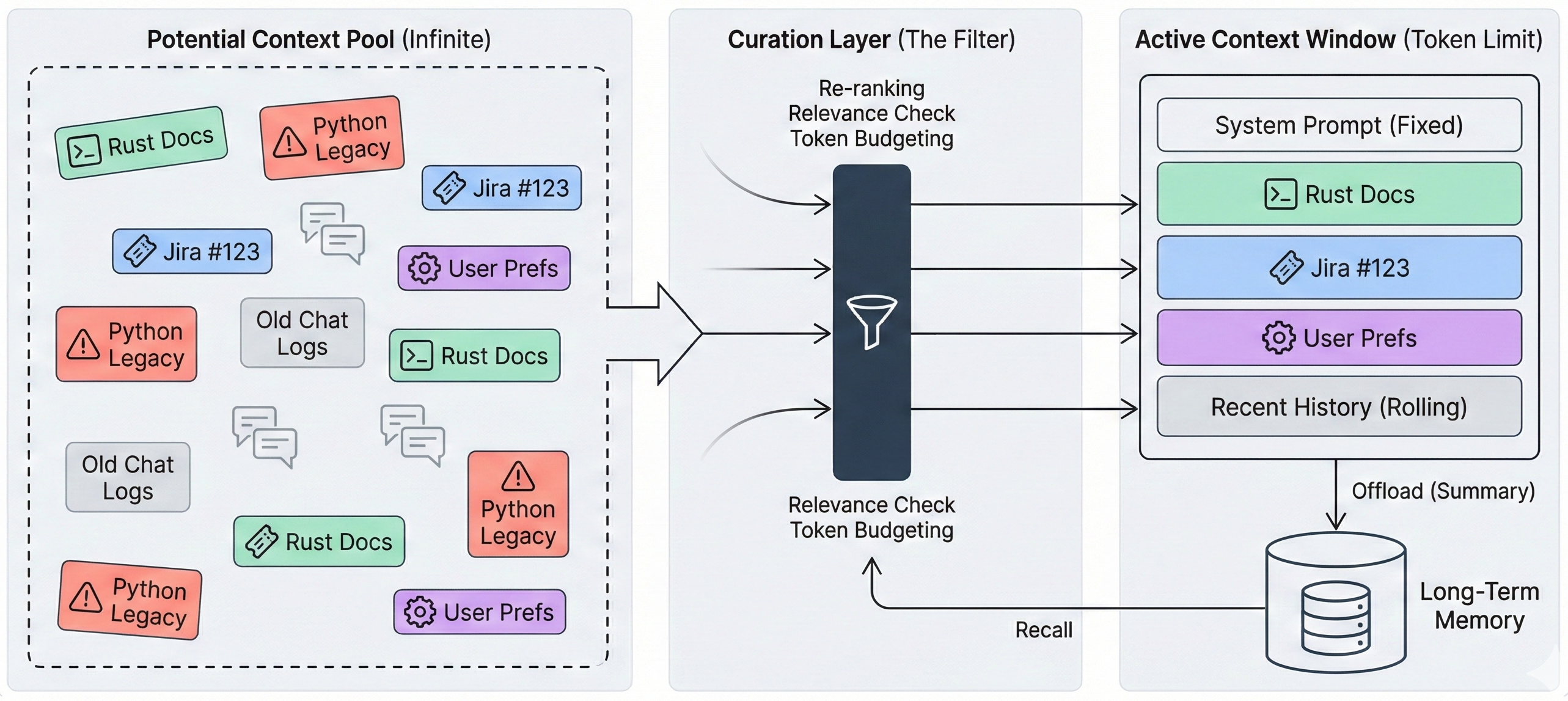
Why "More Context" Isn't Better
The first failure mode is what I call context rot. As context accumulates superfluous content old tool outputs, intermediate reasoning steps, irrelevant chatter the model's instruction-following degrades. It "drifts," recycling past actions or focusing on irrelevant details rather than the current query.
The Delta-Update Protocol (ACE)
To combat Context Collapse the phenomenon where iterative rewriting compresses detailed heuristics into generic summaries we've moved toward delta-based context management. The ACE (Agentic Context Engineering) framework, introduced by Zhang et al. (2025), formalized this by treating the system prompt not as a static text block, but as an evolving "Playbook" of structured bullets.30
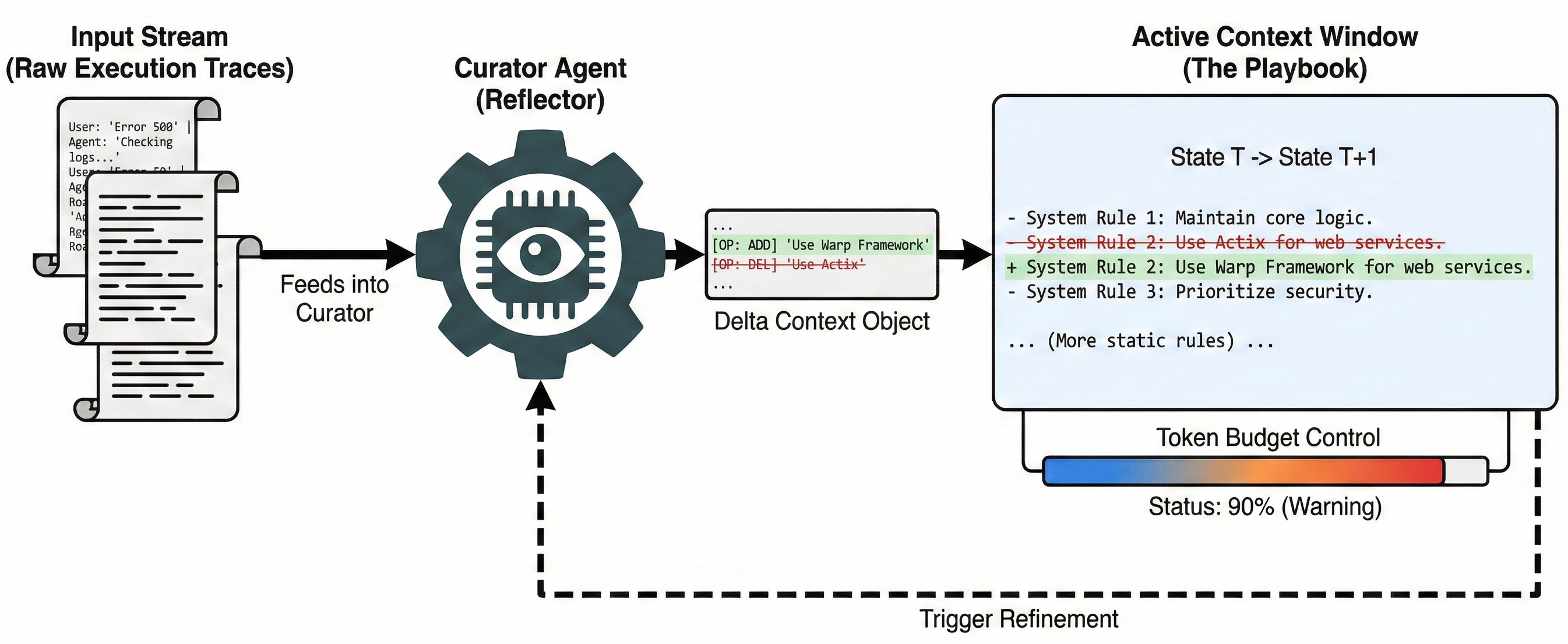
Instead of monolithic rewriting (which incurs high latency and "Brevity Bias"), ACE decouples the context lifecycle into three deterministic roles:
- Generator: Produces reasoning trajectories and execution traces.
- Reflector: Critiques traces to extract strictly additive insights or corrections.
- Curator: Synthesizes insights into Delta Contexts atomic
ADD,UPDATE, orDELETEoperations applied to the Playbook.
This architecture enables a "Grow-and-Refine" strategy. The context accepts incremental writes during execution (Grow) and performs lazy deduplication via semantic embedding comparisons only when the token budget is reached (Refine). Empirical results show this approach reduces adaptation latency by ~87% while preventing the information loss inherent in summarization-based memory 30.
from enum import Enum
from dataclasses import dataclass
class DeltaOp(Enum):
ADD = "add"
UPDATE = "update"
DELETE = "delete"
@dataclass
class DeltaContext:
"""Atomic context mutation for the ACE Curator role."""
operation: DeltaOp
key: str # Semantic identifier (e.g., "user_preference_shoes")
content: str | None # New content (None for DELETE)
embedding: list[float] | None = None # For deduplication
class PlaybookCurator:
"""
Maintains an evolving system prompt as structured bullets.
Implements 'Grow-and-Refine' strategy from ACE framework.
"""
def __init__(self, max_bullets: int = 50, similarity_threshold: float = 0.9):
self.bullets: dict[str, str] = {}
self.embeddings: dict[str, list[float]] = {}
self.max_bullets = max_bullets
self.threshold = similarity_threshold
def apply(self, delta: DeltaContext):
if delta.operation == DeltaOp.ADD:
if not self._is_duplicate(delta):
self.bullets[delta.key] = delta.content
self.embeddings[delta.key] = delta.embedding
elif delta.operation == DeltaOp.UPDATE:
self.bullets[delta.key] = delta.content
elif delta.operation == DeltaOp.DELETE:
self.bullets.pop(delta.key, None)
self._refine_if_needed()
def _is_duplicate(self, delta: DeltaContext) -> bool:
"""Lazy deduplication via embedding similarity."""
for existing_emb in self.embeddings.values():
if cosine_similarity(delta.embedding, existing_emb) > self.threshold:
return True
return False
def _refine_if_needed(self):
"""Merge similar bullets when capacity is reached."""
if len(self.bullets) > self.max_bullets:
# Cluster and summarize (implementation omitted for brevity)
passContext Poisoning
There's also a more insidious failure mode. A striking case study from DeepMind illustrates this: a Gemini agent playing Pokémon misread the game state and recorded an incorrect goal in its context. Because the model attends to its own previous outputs as ground truth, the error was reinforced in a feedback loop. The agent became fixated on an impossible objective, ignoring valid game updates because its "poisoned" context overrode new information.25
Engineering Principles
So what actually works? Three patterns have emerged from production deployments:
Context Compaction. Strategies like structured note-taking (agents write summaries to persistent files) and explicit context clearing are essential for maintaining coherence in long-horizon tasks. The key is to be aggressive about what gets evicted.
Re-ranking. Placing critical information at the beginning and end of prompts exploits the primacy/recency effects, avoiding the "lost in the middle" dead zone.
The DRIFT Framework. Context engineering has security implications too. DRIFT (Dynamic Rule-based Isolation Framework for Trustworthy systems) uses a Dynamic Validator to detect deviations from the initial plan and an Injection Isolator to mask instructions that conflict with user intent.26
Key Insight: Context is not storage it is attention. Managing context is managing what your agent thinks about.
Production Realities and the Path Forward
The Reliability Gap
Here's the uncomfortable truth. While LLMs have achieved human-level performance on many academic benchmarks, agentic systems have not. The failure rate for autonomous multi-agent systems in production remains stubbornly high Augment Code reports 40-80% due to coordination, state management, and specification issues.27
The path forward lies not in training larger models, but in better systems engineering:
- Context Engineering: Managing the attention budget as a finite resource
- Explicit Memory Management: Treating memory as a temporal, causal graph not a vector bucket
- SRE Practices: Observability, loop detection, and circuit breakers applied to stochastic AI
Verification Logic: The Unit Test for Retrieval
To mitigate the MAST failure modes, we've started introducing Deterministic Verification Layers. The idea is simple: a retrieval is not accepted until it passes a verification predicate. This "assert-then-inject" pattern prevents the "Garbage In, Hallucination Out" loop common in naive RAG pipelines.
Here's a simplified version of what that looks like:
def verify_retrieval(query: str, retrieved_chunks: list[str]) -> bool:
"""
Verifies retrieval relevance before context injection.
Prevents 'Context Poisoning' from irrelevant chunks.
"""
# 1. Syntactic Check: Does chunk contain query entities?
query_entities = extract_ner(query)
chunk_entities = [extract_ner(c) for c in retrieved_chunks]
if intersection(query_entities, chunk_entities) == 0:
return False # Fail fast: Graph/Vector retrieved unrelated concepts
# 2. Entailment Check (Small Model)
# Uses a specialized 3B parameter NLI (Natural Language Inference) model
# strictly for entailment, cheaper than the main reasoning model.
for chunk in retrieved_chunks:
if nli_model.predict(premise=chunk, hypothesis=query) == "contradiction":
# Critical: Identify 'Anti-facts' (e.g., "Product X is NOT available")
flag_contradiction(chunk)
return TrueThe Future: Learned Memory Management
The cutting edge moves beyond heuristic-based management ("always summarize after 10 turns") to learned behaviors. This is where things get exciting.
ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers) uses reinforcement learning to let agents discover optimal tool-use strategies. Instead of scripted retrieval, the agent is rewarded for achieving correct outcomes learning when to read/write memory without hard-coding.28
Memory-R1 applies RL specifically to memory operations. The key insight is to model memory management not as a heuristic rule (e.g., "summarize every $N$ turns"), but as a sequential decision-making problem formalized as a Partially Observable Markov Decision Process (POMDP).
The formalism looks like this:
- State ($S_t$): The tuple $(C_t, M_t)$, where $C_t$ is the current context window content and $M_t$ is the external memory state.
- Action Space ($A$): A discrete set of memory operations:
WRITE(k, v): Commit fact to long-term storage.UPDATE(k, v): Modify existing record (handling temporal invalidation).FORGET(k): Explicit deletion of noise.NOOP: Do nothing (preserve attention budget).
- Policy ($\pi$): $\pi(a_t | S_t)$ maps the current state to the optimal memory operation.
The training signal is particularly clever. Unlike standard RLHF which rewards "helpfulness," Memory-R1 utilizes a dual-objective reward function:
$R = R_{task} - \lambda C_{ops}$
Where $R_{task}$ is the success of the downstream query (did the memory help answer the question?) and $C_{ops}$ is a cost penalty for memory operations. This forces the model to learn information sparsity: only write to memory if it significantly reduces future entropy.
In production tests, this RL approach reduced storage ops by 60% while increasing retrieval accuracy on multi-hop temporal queries by 22% compared to heuristic baselines.29 Those numbers suggest we're only scratching the surface.
Conclusion: From Stateless Search to Stateful Cognition
If this trajectory tells us anything, it's that the evolution from RAG to Agent Memory represents a fundamental shift in how we architect AI systems:
| Paradigm | Data Unit | Retrieval Logic | State |
|---|---|---|---|
| Traditional RAG | Text Chunk | Vector Similarity | Stateless |
| GraphRAG | Entity/Node | Graph Traversal | Stateless |
| Agentic RAG | Tool Output | Multi-step Planning | Transient (loop) |
| Agent Memory | Fact/Episode | Contextual + Temporal | Persistent |
The illusion that RAG provides "grounding" is fading. We now understand that RAG is a mechanism for contextualization, but true grounding requires a system that can persist state, resolve temporal conflicts, and maintain structural integrity against the entropy of probabilistic generation.
What comes next? I suspect the future belongs to architectures that can bridge the gap between the fluid, probabilistic nature of the LLM and the rigid, deterministic requirements of the real world. This transition from "Stateless Search" to "Stateful Cognition" is, in my view, the defining trajectory of AI development in this decade.
We're not there yet. But we're learning.